
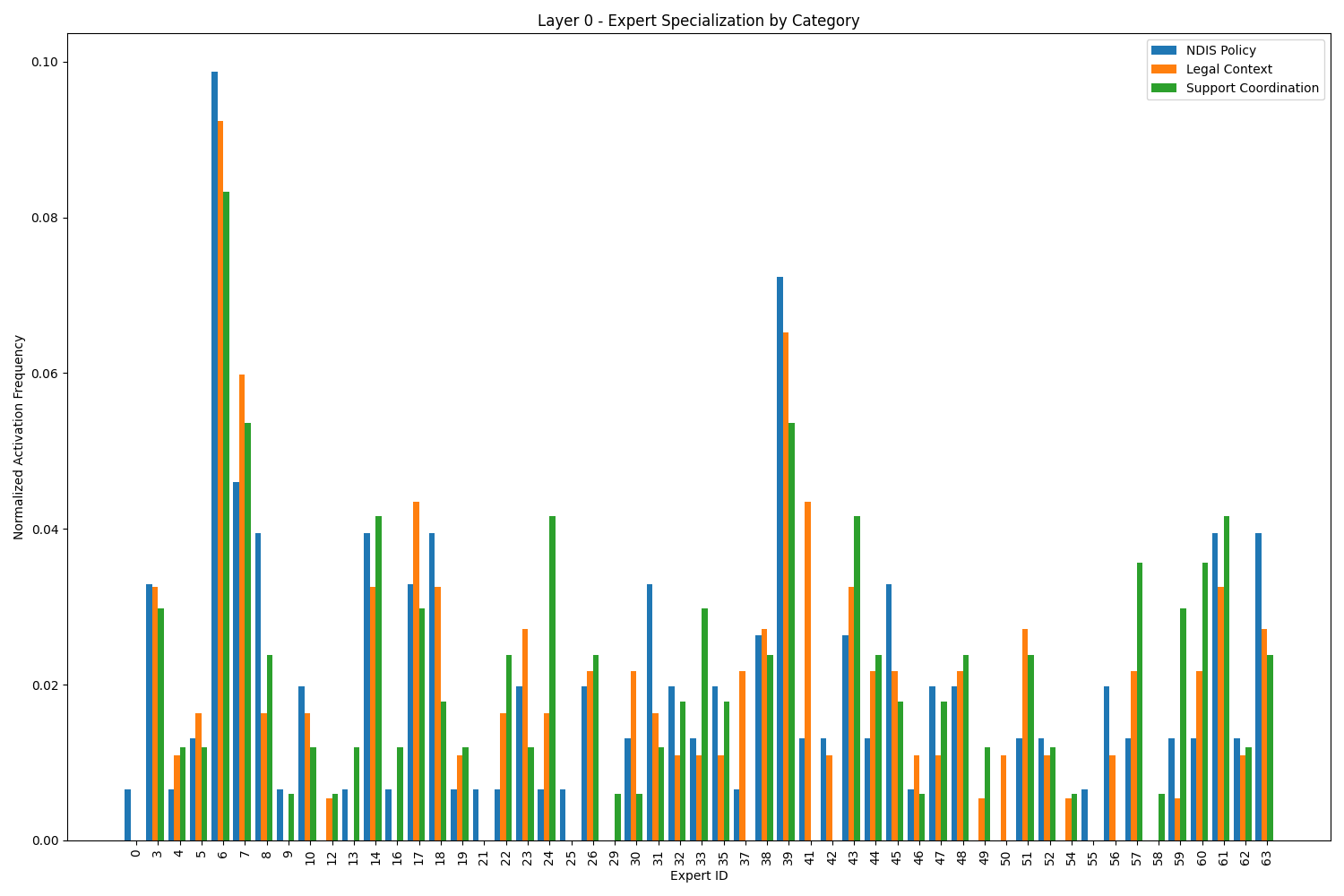
Our aXbot project is now advancing with in-depth analysis of the OLMoE-1B-7B model’s Mixture-of-Experts architecture. This innovative model utilizes 64 specialized neural network modules (experts) per layer, selectively activating only 8 for each input token. Our current analysis tracks how these experts respond differently to NDIS policy, legal context, and support coordination queries – critical domains for our NDIS advocacy assistant. By understanding which experts specialize in handling disability support information, we can optimize our QLoRA fine-tuning approach, targeting specific areas of the model for adaptation. This tailored approach will help aXbot deliver more accurate, context-appropriate responses while maintaining the distinctive “Axel” persona that makes our assistant uniquely approachable and effective for NDIS participants.
Mixture of Experts (MoE) Explained
Mixture of Experts (MoE) is a neural network architecture that uses a “divide and conquer” approach. Instead of running all inputs through the entire network, MoE selectively activates only a subset of its components (called “experts”) for each input.
The key components are:
- Experts: Specialized neural network modules that each handle different aspects of the task or language.
- Router: A component that decides which experts should process each input token.
- Sparse Activation: Only a small subset of experts (e.g., 8 out of 64) is activated for each token, making processing more efficient.
MoE models like OLMoE-1B-7B have many total parameters (7B) but use only a fraction (1B) for processing each token. This approach offers several benefits:
- Efficiency: Less computation per token compared to dense models of similar capability
- Specialization: Experts can focus on specific domains or linguistic features
- Capacity: Larger total parameter count enables storing more knowledge
This architecture allows MoE models to achieve performance similar to much larger dense models while using significantly less computational resources during inference.
OLMoE Architecture Overview
- Base Architecture: OLMoE-1B-7B is a transformer-based language model (similar to LLaMA, GPT, etc.) but with a sparse MoE design.
- Total vs. Active Parameters:
- Total parameters: ~7 billion (7B) parameters
- Active parameters: ~1 billion (1B) parameters per token
- Mixture-of-Experts Structure:
- 16 transformer layers
- 64 experts per layer
- Only 8 of those 64 experts are activated for each token
- This sparse activation is what makes the model efficient
- Router Network:
- For each token in the input, a “router” component decides which 8 experts (out of 64) should process that token
- The router assigns different weights to each expert, determining how much that expert contributes to the output
- Expert Specialization:
- Different experts tend to specialize in different aspects of language
- Some might focus on syntax, others on domain-specific knowledge, etc.
What the Visualizations Show
- Expert Activation Counts:
- The bar charts show how often each expert was activated for each query type
- Higher bars indicate experts that were activated more frequently
- Specialization Patterns:
- If you see different activation patterns across query types (NDIS Policy vs. Legal Context vs. Support Coordination), this indicates expert specialization
- For example, if expert #42 is highly active for NDIS Policy queries but rarely active for Legal Context queries, it suggests that expert #42 has specialized in NDIS-related knowledge
- Layer Differences:
- Early layers (0-3) typically handle more basic linguistic features
- Middle layers (4-11) often handle more complex semantic understanding
- Later layers (12-15) typically handle high-level reasoning and domain-specific knowledge
- Compare visualizations across layers to see how specialization evolves
This analysis helps you understand which experts are most relevant for different query types, which is valuable information when we fine-tune the model for specific domains using techniques like QLoRA.